1. Introduction
A linguagem C é amplamente utilizada em sistemas embarcados e de tempo real por sua eficiência e proximidade com o hardware. Essa mesma característica, porém, torna a linguagem permissiva: operações válidas em C podem introduzir falhas graves sem qualquer alerta em tempo de compilação.
Nesta serie de artigos será explorado o impacto de problemas históricos de software que ocasionaram acidentes reais. Para este primeiro volume, será analisado um dos exemplos mais conhecidos de falhas que ocasionaram um acidente terrível, o famoso caso Therac-25, no qual erros como de sincronização e controle de estado em software resultaram em overdoses de radiação e mortes de pacientes.
Neste artigo, esses problemas são revisitados de forma prática, por meio da simulação de bugs inspirados no Therac-25 em um sistema embarcado real executando FreeRTOS, destacando como erros silenciosos surgem e como podem ser evitados.
Therac-25

O Therac-25 era um acelerador linear médico projetado pela Atomic Energy of Canada Limited (AECL) para tratamento de câncer. Entre 1985 e 1987, a máquina administrou overdoses massivas de radiação em pelo menos seis pacientes, resultando em mortes e ferimentos graves. As investigações revelaram que os acidentes não foram causados por uma única falha isolada, mas por uma combinação de erros de programação (race conditions), falhas graves de engenharia de sistemas e uma cultura organizacional de excesso de confiança no software como mecanismo primário de segurança. Abaixo estão descritos dois dos maiores problemas de projeto e implementação identificados nas investigações.
Problema 1: Race Condition
- O software era multitarefa preemptivo, com diversas tarefas acessando variáveis globais compartilhadas.
- Não havia mecanismos adequados de sincronização (mutex, semáforos ou operações atômicas).
- Flags e variáveis de controle eram lidas e escritas de forma não atômica, ou seja, essas ações poderiam ser interrompidas antes de sua conclusão.
- O operador frequentemente selecionava o modo "X" (Raio-X), percebia o erro e alterava rapidamente para "E" (Elétron).
O bug:
O software levava aproximadamente 8 segundos para configurar os ímãs de curvatura responsáveis pela seleção de energia.
Se o operador corrigisse o modo e pressionasse Enter dentro desse intervalo, ocorria uma condição de corrida (Race condition) entre a tarefa de entrada de dados e as tarefas de configuração do hardware. Como resultado, o sistema avançava
para a fase de tratamento antes que todas as variáveis internas fossem atualizadas de forma consistente.
Resultado:
- A interface indicava corretamente o modo "Elétron", mas internamente o sistema configurava a máquina com parâmetros de alta energia típicos do modo "Raio-X", sem o alvo e o filtro de espalhamento posicionados. Isso resultava em um feixe de elétrons altamente concentrado e de intensidade letal.
- ➡️ Bug silencioso clássico: o sistema aparentava estar em um estado seguro, enquanto internamente operava em uma condição fisicamente inválida.
E o que é race condition?
Uma race condition ocorre quando múltiplos contextos de execução acessam e modificam um recurso compartilhado sem sincronização adequada, fazendo com que o resultado final dependa da ordem não determinística de execução. Seria como se em um jogo de futebol jogadores do mesmo time compitam ferozmente pela posse da bola sem jogar em equipe, sem sincronização e cada vez que um deles fosse fazer o gol o outro não deixasse este jogador finalizar e tomaria a bola fazendo com que o gol nunca acontecesse ou fosse para fora do alvo.
Como exemplo, um pouco mais técnico dessa vez, em sistemas de tempo real, considere duas tarefas que transmitem mensagens pela mesma interface UART. Uma tarefa precisa enviar a string "Deveria ter usado semáforo", enquanto outra precisa enviar "Preciso implementar uma seção crítica". Em um sistema preemptivo, uma tarefa pronta e de maior prioridade pode interromper a execução da outra a qualquer momento.
Se a transmissão de caracteres não for protegida por mecanismos de sincronização, como semáforos ou seções críticas, as tarefas podem ser interrompidas antes de concluir suas respectivas escritas. Como resultado, os bytes enviados à UART podem se intercalar de forma imprevisível, produzindo uma saída corrompida e sem significado, como "Deprericia so… usado seção".
Esse comportamento não representa um erro de compilação ou de lógica isolada, mas sim uma consequência direta da concorrência não controlada. O sistema passa a exibir um comportamento não planejado e não determinístico, caracterizando uma race condition.
[TASK A] Deveria ter usado semáforo
[TASK B] Preciso implementar uma seção crítica
Deveria Pterec iusoa rui msapdl eamnetsáorçãfoo
crítica
Problema 2: Estouro de variável (Integer Overflow)
- O software utilizava variáveis inteiras de tamanho reduzido para armazenar contadores, estados e valores acumulados relacionados à operação do equipamento.
- Não havia validação explícita de limites antes de operações aritméticas, assumindo-se implicitamente que os valores nunca ultrapassariam a capacidade do tipo.
- O código era escrito em C, linguagem que não fornece qualquer mecanismo automático de detecção de estouro de variáveis inteiras.
O bug:
Quando uma variável inteira atinge o valor máximo que pode ser representado
pelo seu tipo e sofre um incremento adicional, ocorre um estouro de variável.
Em inteiros sem sinal, o valor simplesmente “volta” para zero e continua a contar.
Esse comportamento acontece de forma silenciosa, sem erro de compilação,
sem exceção em tempo de execução e sem qualquer alerta ao software.
Resultado:
- No Therac-25, variáveis relacionadas a estado operacional e parâmetros de tratamento podiam sofrer esse tipo de estouro, permitindo que o sistema avançasse para fases perigosas da operação enquanto aparentava estar em um estado seguro.
- ➡️ Bug silencioso clássico: o valor interno da variável parece válido, mas representa um estado logicamente impossível do ponto de vista do projeto do sistema.
Fundamentos: tipos, memória e arquitetura em C
Diferentemente de linguagens de alto nível que abstraem completamente a memória, a linguagem C exige que o programador declare explicitamente o tipo e o tamanho das variáveis utilizadas pelo software, se for feita uma alocação estática. Essa declaração informa ao compilador quanto espaço de memória deve ser reservado para armazenar cada dado, seja na stack ou em memória estática como .bss ou .data.
Tipos fundamentais como char, int, float e
double não representam apenas categorias semânticas, mas
quantidades finitas de bits. Esses bits determinam o intervalo
de valores que podem ser representados e, consequentemente, os limites aritméticos
de cada variável.
É importante destacar que a linguagem C não fixa o tamanho absoluto
de vários tipos primitivos. O padrão define apenas tamanhos mínimos e relações
entre eles. Por exemplo, o tipo int deve ter pelo menos 16 bits, mas
seu tamanho real depende da arquitetura do processador e do modelo de dados adotado
pelo compilador.
Em sistemas de 32 bits, é comum que int ocupe 32 bits. Em sistemas de
64 bits, o tipo int pode legalmente possuir 64 bits segundo o padrão
da linguagem, embora na prática permaneça com 32 bits na maioria das plataformas.
Nesses sistemas, tipos como long e ponteiros frequentemente passam a
ocupar 64 bits.
Dessa forma, o tamanho efetivo dos tipos em C não depende apenas da linguagem, mas também da arquitetura do processador e do ABI (Application Binary Interface), que define as regras de representação binária e interoperabilidade entre programas compilados.
Essa característica, amplamente discutida em obras clássicas como :contentReference[oaicite:0]{index=0} e :contentReference[oaicite:1]{index=1}, é uma das razões pelas quais C oferece grande controle sobre o hardware, mas também exige disciplina rigorosa do programador.
E o que é o estouro de variável?
O estouro de variável ocorre quando uma operação aritmética produz um valor que não pode ser representado pelo tipo de dado utilizado para armazená-lo. Como cada tipo possui um número fixo de bits, seu intervalo de valores é necessariamente limitado.
Em linguagem C, esse evento não é tratado automaticamente. O compilador não insere verificações de estouro em tempo de execução, e o software continua sua execução normalmente, mesmo após o valor ultrapassar os limites representáveis.
No caso de inteiros sem sinal, quando o valor máximo é
ultrapassado, o resultado retorna ao início do intervalo. Por exemplo, um
uint8_t possui 8 bits e pode representar valores de 0 a 255; ao
somar 1 ao valor 255, o resultado passa a ser 0. Do ponto de vista do compilador e da linguagem, esse valor continua sendo
perfeitamente válido. No entanto, do ponto de vista lógico do
sistema, ele pode representar um estado completamente impossível ou perigoso.
Esse é o motivo pelo qual esse tipo de falha é classificado como
bug silencioso de alta periculosidade!.
Em sistemas embarcados, de tempo real e especialmente em sistemas críticos, esse comportamento é ainda mais perigoso. Estados internos podem ser corrompidos sem qualquer exceção, interrupção ou mensagem de erro, afetando diretamente verificações de segurança, temporizações, limites físicos ou estados de controle. A literatura de sistemas críticos, incluindo diretrizes como MISRA-C e recomendações discutidas em obras como :contentReference[oaicite:2]{index=2}, enfatiza que o simples uso incorreto de tipos inteiros pode ser suficiente para comprometer a previsibilidade e a segurança de um sistema.
Exemplo simplificado em C:
Estouro silencioso de variável inteira
#include <stdint.h>
int main(void)
{
uint8_t counter = 250;
counter += 10;
while (counter < 100)
{
// loop inesperado
}
return 0;
}
O que o programador espera:
O valor inicial de counter é 250. Após o incremento de 10, o valor
esperado seria 260, fazendo com que a condição do while fosse falsa
e o laço não fosse executado.
O que realmente acontece:
A variável counter é do tipo uint8_t, que só consegue
armazenar valores entre 0 e 255. Ao tentar armazenar o valor 260, ocorre um
estouro e o valor resultante passa a ser 4 (260 módulo 256).
- O código compila normalmente.
- O programa executa sem travar.
- Nenhum erro é sinalizado pelo sistema.
- A lógica de controle do software é alterada silenciosamente.
Resultado:
-
A condição
counter < 100torna-se verdadeira, levando o sistema a entrar em um laço inesperado ou a seguir um caminho lógico não previsto.
Teste prático
O objetivo deste experimento é demonstrar, de forma prática e observável em hardware real, a ocorrência simultânea de race condition e overflow silencioso de variável em um sistema multitarefa preemptivo. O cenário foi intencionalmente simplificado para evidenciar como falhas sutis em C podem produzir estados logicamente impossíveis, apesar de o programa permanecer aparentemente funcional.
Ambiente e ferramentas utilizadas
- Placa de desenvolvimento AM243x LaunchPad Development Kit (Texas Instruments), baseada em núcleo ARM Cortex-R5F, representativa de sistemas embarcados de tempo real com requisitos de determinismo.
- FreeRTOS, executando em modo preemptivo, permitindo concorrência real entre múltiplas tarefas.
- MCU+ SDK da Texas Instruments, utilizando como base o exemplo UART Echo com FreeRTOS, empregado apenas como infraestrutura mínima de inicialização do sistema operacional.
- Code Composer Studio (CCS) (versão 20.3.0.14__1.9.0), utilizado para compilação, carga do firmware e depuração via JTAG.
-
Instrumentação por meio do CIO (C I/O) do CCS, mecanismo no qual
funções como
DebugP_logsão redirecionadas pelo debugger via JTAG, permitindo observar o comportamento interno do sistema sem utilizar UART física e sem interferir diretamente no escalonamento das tarefas.
Ideia central do experimento
Neste experimento é utilizada uma variável global de estado, compartilhada entre múltiplas tarefas de um sistema multitarefa preemptivo. Essa variável representa um estado interno do sistema e é manipulada concorrentemente por duas tarefas independentes, sem qualquer mecanismo de proteção, como mutexes, seções críticas ou operações atômicas.
Cada tarefa atualiza a mesma variável global utilizando taxas de crescimento diferentes e períodos distintos de execução. Uma tarefa incrementa o estado de forma lenta e incremental, enquanto a outra aplica incrementos maiores e mais frequentes. Essa combinação cria, de forma intencional, um cenário clássico de race condition, no qual o valor final da variável passa a depender da ordem não determinística de execução das tarefas.
Além disso, a variável de estado foi propositalmente definida com um tipo inteiro
de largura reduzida (uint8_t), tornando inevitável a ocorrência de
overflow silencioso. O resultado observado é um estado que permanece
válido do ponto de vista da linguagem C, mas que assume valores
logicamente impossíveis sob a ótica do sistema.
O objetivo do experimento não é provocar falhas explícitas ou travamentos, mas demonstrar como falhas silenciosas podem surgir em sistemas aparentemente funcionais quando variáveis globais são compartilhadas de forma insegura em ambientes preemptivos.
Variável global compartilhada sem proteção
volatile uint8_t system_state = 0;
A variável system_state representa o estado global do sistema.
O qualificador volatile informa ao compilador que o valor da variável pode mudar a qualquer momento, impedindo que ele otimize o acesso mantendo o valor em um registrador. No entanto, o volatile não garante atomicidade, não cria barreiras de memória (memory barriers) e não substitui mecanismos de sincronização de hardware.
Task A — Atualização incremental do estado
void OperatorTask(void *pvParameters)
{
(void)pvParameters;
for (;;)
{
system_state++; /* Escrita não atômica */
vTaskDelay(pdMS_TO_TICKS(200));
}
}
Esta tarefa simula uma interação gradual com o sistema, incrementando o estado
global de forma periódica. A operação system_state++ não é atômica
e envolve múltiplas etapas internas (leitura, cálculo e escrita), tornando-se
vulnerável à preempção por outras tarefas.
Task B — Atualização concorrente e mais agressiva
void ControlTask(void *pvParameters)
{
(void)pvParameters;
for (;;)
{
system_state += 10; /* Escrita concorrente */
vTaskDelay(pdMS_TO_TICKS(150));
}
}
Esta tarefa representa uma lógica interna de controle do sistema e modifica a mesma variável global, porém com incrementos maiores e maior frequência. Executando em paralelo com a tarefa do operador, ela cria uma condição de corrida real, na qual atualizações podem ser sobrescritas ou perdidas.
Task de monitoramento do estado global
void LoggerTask(void *pvParameters)
{
(void)pvParameters;
for (;;)
{
DebugP_log(
"[tick=%lu] system_state=%u\r\n",
xTaskGetTickCount(),
system_state
);
vTaskDelay(pdMS_TO_TICKS(500));
}
}
A tarefa de monitoramento observa passivamente o valor do estado global e registra sua evolução ao longo do tempo por meio do mecanismo de C I/O (CIO) do ambiente de depuração. Essa separação permite coletar evidências do problema sem interferir diretamente no comportamento das tarefas que manipulam o estado.
Criação das tarefas e preempção
void freertos_main(void *args)
{
(void)args;
xTaskCreate(OperatorTask, "Operator", 1024,
NULL, tskIDLE_PRIORITY + 2, NULL);
xTaskCreate(ControlTask, "Control", 1024,
NULL, tskIDLE_PRIORITY + 3, NULL);
xTaskCreate(LoggerTask, "Logger", 1024,
NULL, tskIDLE_PRIORITY + 1, NULL);
vTaskDelete(NULL);
}
As tarefas são criadas com prioridades distintas, garantindo a ocorrência de preempção. Como não há qualquer forma de sincronização, o valor final da variável global passa a depender da ordem de execução das tarefas, resultando em race conditions e overflows silenciosos, observáveis diretamente nos logs do sistema.
Teste output
Após algum tempo com o código executando, a saída observada no terminal de depuração via CIO está registrada na imagem abaixo
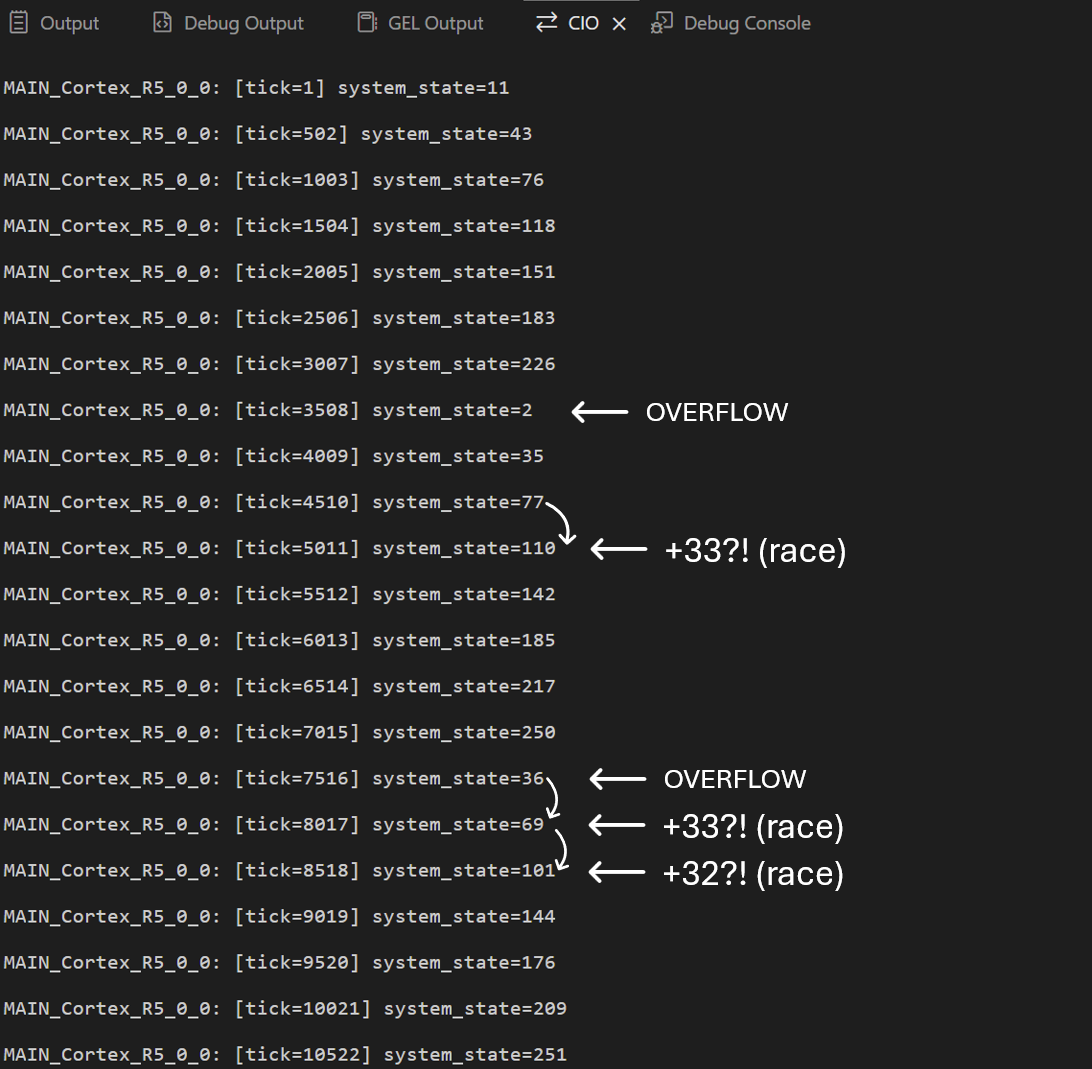
A saída apresentada evidencia de forma clara a ocorrência simultânea de
race condition e overflow silencioso de variável.
Observa-se inicialmente um crescimento aparentemente consistente do valor de
system_state, resultado da atuação concorrente das duas tarefas.
Entretanto, ao atingir valores próximos ao limite máximo do tipo
uint8_t, ocorrem transições abruptas para valores baixos, como a
passagem de 226 para 2 e de 250 para 36, caracterizando overflow por
aritmética modular.
Neste experimento, duas tarefas distintas escrevem na mesma variável global
system_state sem qualquer tipo de proteção. A primeira tarefa incrementa
essa variável lentamente, somando 1 a cada execução. A segunda tarefa também escreve
no mesmo estado, porém de forma mais agressiva, somando 10 a cada vez que executa.
Como essas tarefas são escalonadas pelo FreeRTOS de forma preemptiva, não existe
garantia se uma será interrompida no meio
de sua operação.
O comportamento esperado, em um cenário ideal, seria que o valor da variável crescesse
de forma previsível, sempre refletindo a soma desses incrementos. No entanto, o que
se observa na saída é diferente. Em vários momentos, uma tarefa começa a atualizar o
valor de system_state, mas é interrompida antes de concluir a operação.
Enquanto isso, a outra tarefa utiliza esse valor parcial como base para seu próprio
incremento. Quando a primeira tarefa retoma a execução, ela grava um valor calculado
a partir de um estado antigo, sobrescrevendo a atualização feita pela outra tarefa.
Esse entrelaçamento de execuções faz com que alguns incrementos sejam perdidos e outros se combinem de maneira inesperada, produzindo valores que não seguem nenhum padrão regular de crescimento. O resultado é um comportamento não determinístico: o programa continua funcionando, o valor permanece válido para a linguagem C, mas o estado interno do sistema passa a assumir valores incoerentes do ponto de vista lógico. Esse é o efeito clássico de uma race condition combinada com overflow silencioso de variável.
Como Proteger o Sistema?
Em sistemas bem projetados, estados globais não são acessados diretamente por múltiplas tarefas. Em vez disso, o acesso é mediado por uma interface controlada, que centraliza regras de consistência, sincronização e validação de limites, eliminando condições de corrida e falhas silenciosas.
O que foi adicionado no código e por quê
Para corrigir os problemas observados no experimento anterior, o código foi modificado com três objetivos claros: eliminar race condition, evitar overflow silencioso e tornar o acesso ao estado previsível mas controlado.
-
O estado global
system_statepassou a ser privado ao módulo (static), impedindo acesso direto por outras partes do código. -
Foi introduzido um mutex (
SemaphoreHandle_t) para garantir que apenas uma task por vez possa ler ou modificar o estado, eliminando a condição de corrida. -
O acesso ao estado foi encapsulado em uma API segura
(
SystemState_GeteSystemState_Add), evitando escritas diretas na variável global. -
A operação de incremento passou a incluir verificação explícita de
limite, aplicando saturação em
UINT8_MAXpara impedir overflow silencioso.
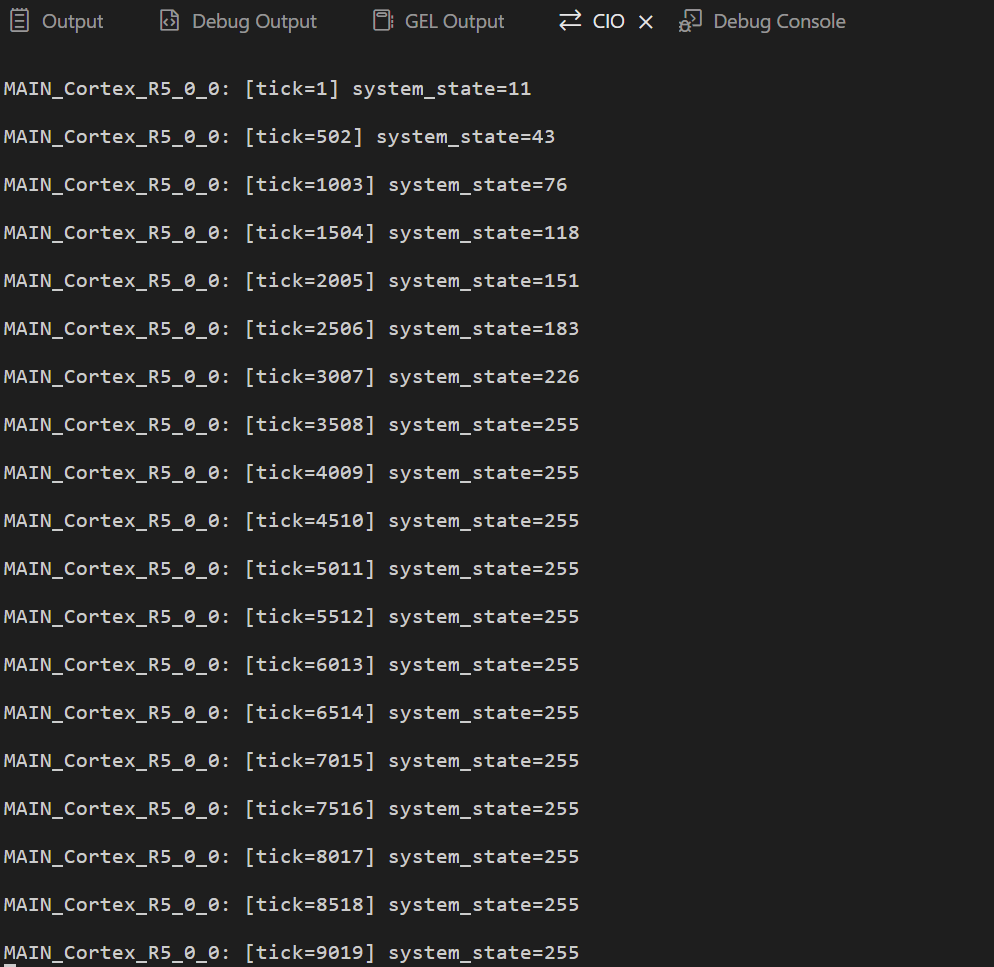
Com essas mudanças, o comportamento do sistema deixa de depender do escalonamento das tarefas e passa a ser determinístico, previsível e seguro, mesmo em um ambiente preemptivo.
Encapsulamento e proteção do estado global
static uint8_t system_state = 0;
static SemaphoreHandle_t state_mutex;
static void SystemState_Add(uint8_t value)
{
xSemaphoreTake(state_mutex, portMAX_DELAY);
if ((uint16_t)system_state + value > UINT8_MAX)
{
system_state = UINT8_MAX; /* saturação */
}
else
{
system_state += value;
}
xSemaphoreGive(state_mutex);
}
Novo output após modificações
Code Availability
O código-fonte do experimento, está disponível no GitHub:


Comentários e discussões