Introdução
De modo geral, processadores são responsáveis por executar as operações em sistemas computacionais, incluindo computadores e microcontroladores. No entanto, um processador isoladamente não é capaz de realizar qualquer tarefa sem acesso às informações que descrevem o que deve ser feito (instruções) e quais dados devem ser processados (entradas).
Para isso, o processador precisa acessar essas informações armazenadas na memória por meio de ciclos de clock — pulsos periódicos que sincronizam todas as operações internas. De forma analógica, cada acesso à memória pode ser entendido como um esforço realizado pelo processador: quanto menor esse esforço, maior a eficiência do sistema em termos de tempo de execução e consumo de energia.
Esse esforço está diretamente relacionado a latência de acesso e à velocidade com que a informação pode ser disponibilizada ao processador após uma solicitação. É exatamente esse aspecto que motiva a existência da hierarquia de memória, um modelo arquitetural que organiza os diferentes tipos de armazenamento de acordo com custo, capacidade e desempenho, além de definir os caminhos pelos quais os dados chegam até a CPU.
Dentro dessa hierarquia surge o protagonista deste artigo: o cache. O cache ocupa um papel central na redução do esforço necessário para acessar informações frequentemente utilizadas, aproximando dados e instruções do processador e, consequentemente, aumentando significativamente o desempenho do sistema.
Entretanto, esse ganho de desempenho vem acompanhado de desafios importantes, especialmente em projetos de software embarcado crítico. Nesses sistemas, características como determinismo temporal e previsibilidade de execução são tão relevantes quanto desempenho bruto, e o uso indiscriminado de cache pode introduzir variabilidade temporal indesejada, ocorrendo muitas vezes em projetos um trade-off entre velocidade e previsibilidade.
Neste artigo, serão explorados os fundamentos do funcionamento do cache, seu papel dentro de uma hierarquia de memória convencional, suas limitações e, principalmente, experimentos práticos em hardware real, demonstrando as características, benefícios e nuances do uso de cache em sistemas embarcados.
First Things First 💡
Antes de entendermos o cache é preciso falar sobre os conceitos de localidade e a hierarquia de memória.o Princípio da Localidade
A ideia central é que programas não acessam a memória de forma aleatória. Eles tendem a focar em "vizinhanças" de dados e instruções. Existem dois tipos:
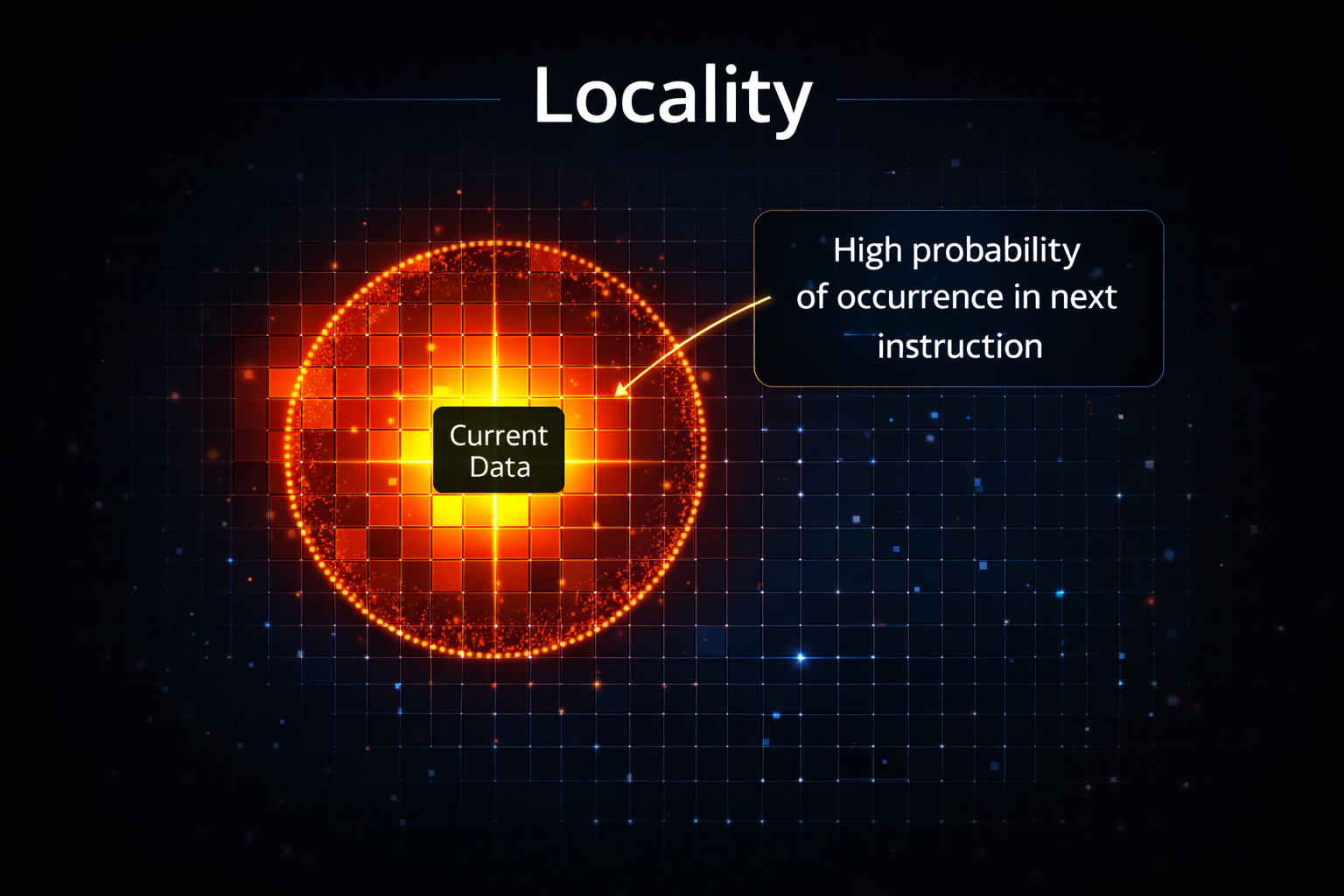
- Localidade Temporal: Se você acessou um dado agora, é muito provável que vá acessá-lo novamente em breve (ex: uma variável de soma dentro de um loop).
- Localidade Espacial: Se você acessou o endereço 100, é muito provável que vá acessar o endereço 104 em seguida (ex: percorrer um array).
Exemplo em C
Loop com boa localidade temporal e espacial
#include <stdint.h>
#define N 1024
uint32_t data[N];
int main(void)
{
uint32_t sum = 0;
for (uint32_t i = 0; i < N; i++)
{
sum += data[i];
}
return 0;
}
Neste exemplo, a variável sum é acessada a cada iteração do loop.
Como o intervalo de tempo entre acessos é pequeno, há boa localidade
temporal em relação a sum.
Já o vetor data é percorrido sequencialmente, no mesmo ordenamento
em que seus elementos estão armazenados na memória. Esse padrão de acesso,
conhecido como stride-1, proporciona boa localidade espacial,
pois acessar data[i] tende a trazer elementos vizinhos para o cache.
Como o corpo do loop apresenta localidade temporal para sum e
localidade espacial para data, a função como um todo possui
boa localidade de memória.
Hierarquia de Memória (um breve briefing)
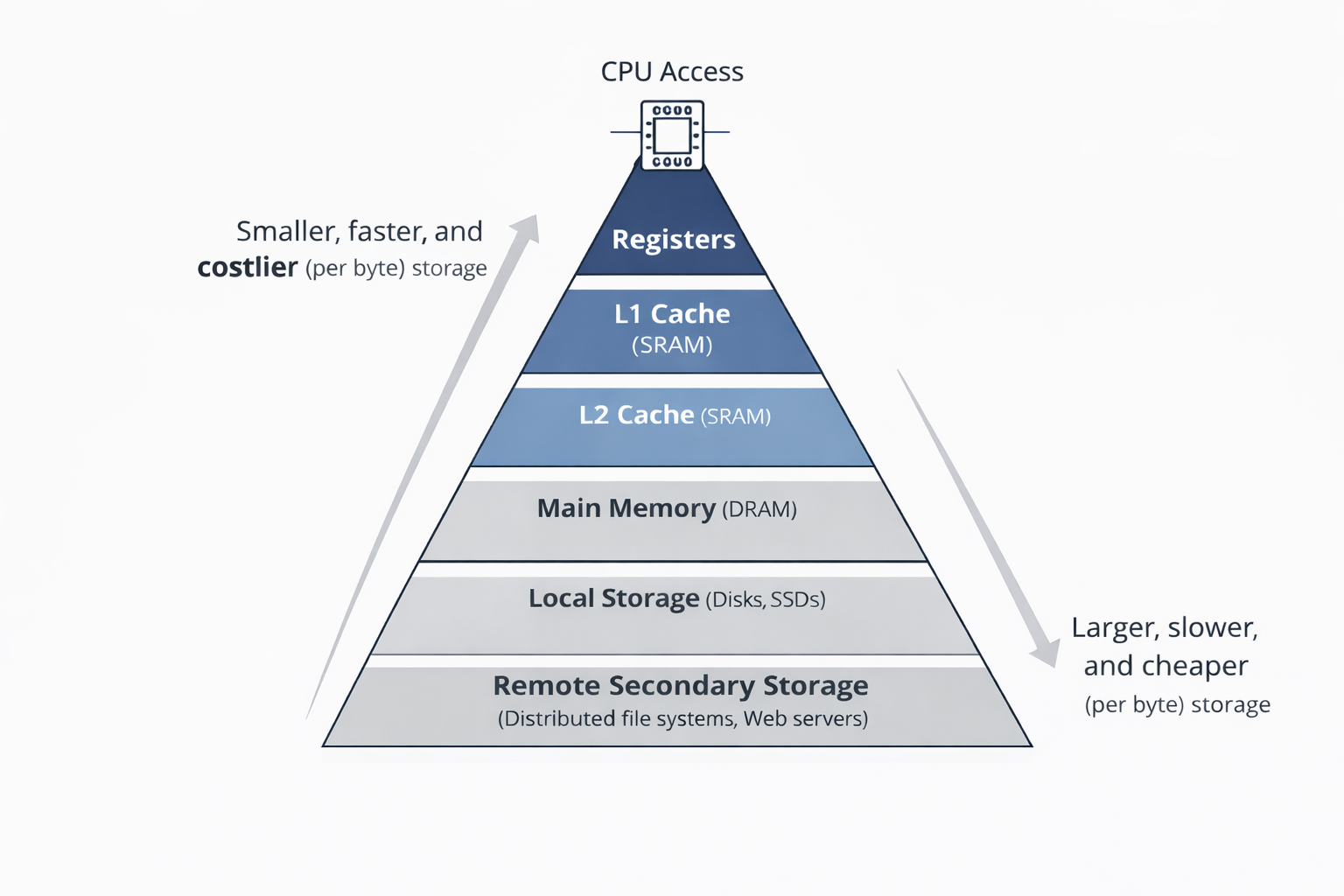
Sistemas computacionais utilizam uma hierarquia de memória porque tecnologias de armazenamento apresentam grandes diferenças de custo, capacidade e latências de acesso. Memórias mais rápidas são menores e mais caras; memórias mais lentas são maiores e mais baratas.
O processador acessa diretamente apenas os níveis superiores dessa hierarquia para coletar os dados e realizar as operações, nível onde estão os registradores. Logo abaixo estão as memórias cache (normalmente do tipo SRAM), que possuem latências de acesso muito baixas, enquanto níveis inferiores, como a DRAM e os discos, possuem latências muito maiores.
É exatamente nesse ponto que o cache começa a fazer sentido.
Programas reais tendem a reutilizar dados recentemente acessados ou a solicitar informações de regiões próximas da memória; o cache explora exatamente esse comportamento para reduzir a latência média de acesso.
A Escala de Tempo de acesso aos dados em memória pelo processador
Para entender o cache, imagine que o processador precisa de um determinado dado: se ele estiver nos Registradores (dentro do chip), o custo é zero, pois o Compilador já planejou o código para que o dado estivesse ali no momento exato em que fosse necessário. Mas, se não estiver, durante o run-time ele buscará no Cache L1, onde será gasto apenas 1 ciclo de clock. Caso o dado também não esteja no L1, precisará buscar no L2, o que fará com que o tempo da operação suba para 10 ciclos. Se ainda assim o dado não for encontrado nos caches, a busca irá para a Memória Principal (RAM) e demoraria 100 ciclos. A diferença se torna ainda mais brutal ao acessar o Disco Local (SSD/HD), onde a espera pula para 10.000.000 de ciclos sob gestão do SO. Por fim, buscar o dado na Web em um Servidor Remoto pode levar até 1.000.000.000 de ciclos. Sem o cache, o processador ficaria ocioso por bilhões de ciclos esperando uma resposta que o cache L1 entrega em apenas um.
Características do uso de cache
O Mecanismo: Hit vs. Miss
- ✅ Cache Hit: O dado solicitado está no cache (local que chamaremos de nível N). Acesso imediato e rápido.
- ⚠️ Cache Miss: O dado não está no nível N. O sistema precisará buscar no nível N+1 da hierarquia de memória, copiando o bloco para o nível superior.
Tipos de Falhas (Misses comuns)
Existem três razões principais para um dado não estar no cache:
- Cold (Compulsory) Miss: O cache está vazio (frio). Comum ao iniciar um programa.
- Conflict Miss: O cache tem espaço, mas múltiplos dados "brigam" pela mesma posição devido à política de posicionamento de hardware.
- Capacity Miss: O conjunto de dados ativos do programa (Working Set) é maior que a capacidade total do cache.
Organização genérica do cache
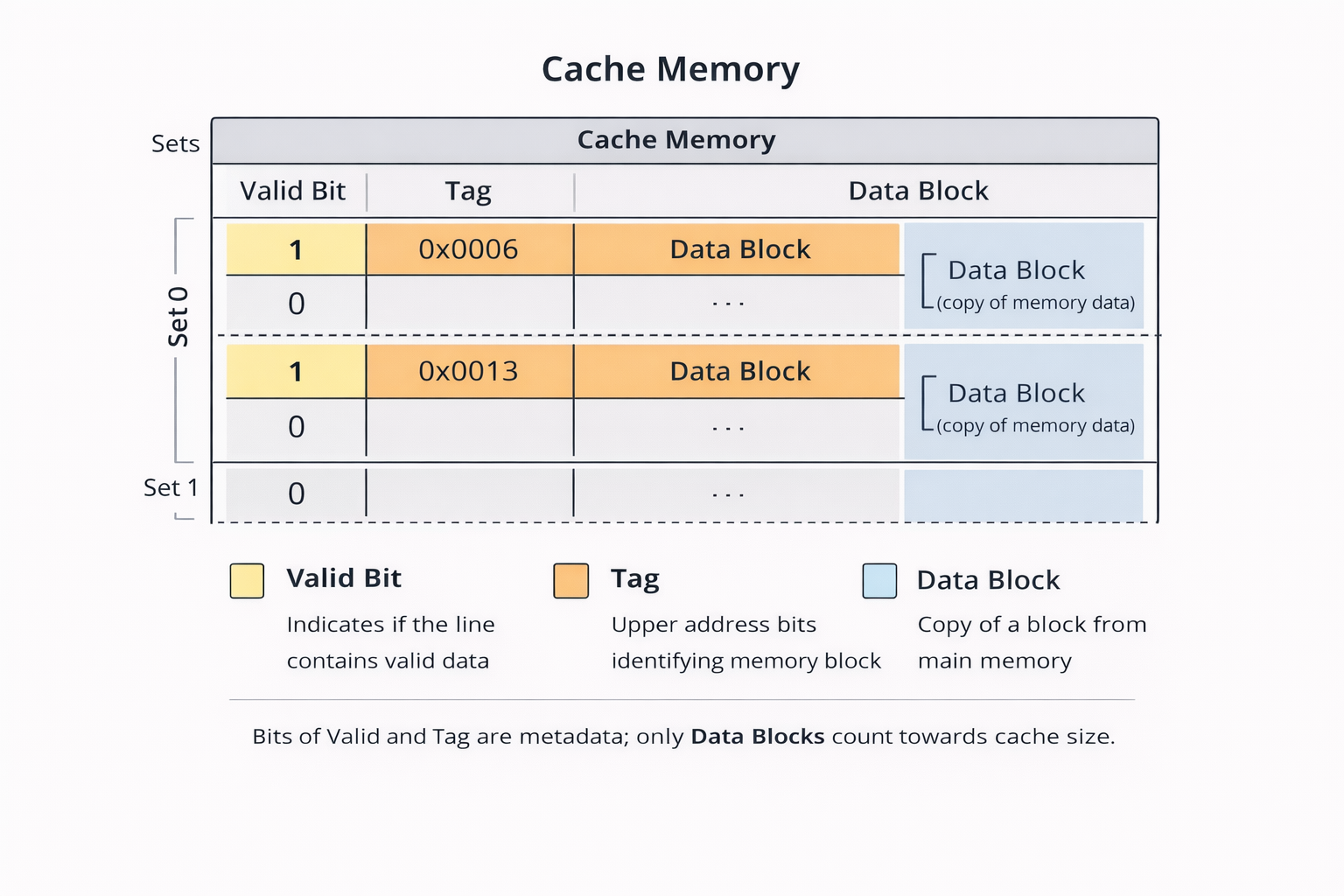
Um cache é organizado como um conjunto de conjuntos (sets). Cada set contém uma ou mais linhas de cache, e cada linha armazena:
- um bloco de dados (copiado da memória principal);
- um bit de validade, que indica se a linha contém dados válidos;
- uma tag, que armazena os bits mais significativos do endereço, identificando de qual bloco da memória principal os dados foram copiados.
O tamanho total do cache é dado apenas pela soma dos blocos de dados. Bits de tag e validade são apenas metadados e não contam como capacidade útil.
Como o cache responde a uma solicitação de acesso
Quando a CPU solicita um dado, o cache executa uma sequência bem definida de etapas:
-
Set Selection
O cache utiliza os bits de set index do endereço para selecionar exatamente um conjunto (set). -
Line Matching (Hit or Miss)
Dentro do conjunto selecionado:- se existir uma linha válida cujo tag corresponda ao endereço, ocorre um cache hit;
- caso contrário, ocorre um cache miss.
-
Word Extraction
Em caso de hit, os bits de block offset indicam onde o dado está localizado dentro do bloco, e ele é retornado imediatamente à CPU. -
Line Replacement on Misses
Em caso de miss, o bloco correspondente é buscado no próximo nível da hierarquia de memória e armazenado no cache, possivelmente substituindo uma linha existente.
⚠️ Impacto do uso de cache no determinismo
O uso de memórias cache melhora, em geral, o desempenho médio de um programa ao reduzir o número de acessos à memória principal, mas esse mesmo mecanismo cria **variação imprevisível nos tempos de acesso à memória**, o que compromete o determinismo da execução de um algoritmo. Isso ocorre porque a latência efetiva de uma operação de leitura/escrita depende do estado interno do cache (isto é, se o dado está presente ou não), de forma que sequências idênticas de instruções podem levar a tempos de execução diferentes em instantes diferentes — fenômeno amplamente documentado na literatura de arquitetura de computadores como uma das principais fontes de variabilidade de tempo de execução em processadores modernos. Essa variabilidade decorre de cache hits e cache misses, políticas de substituição de linhas e conflitos de mapeamento, que tornam o tempo de acesso não determinístico e dependente do histórico de execução. Por essa razão, caches são frequentemente citados em estudos de desempenho como um fator que quebra a previsibilidade temporal de um programa, dificultando análises formais de tempo de execução e levando à necessidade de técnicas especiais quando determinismo estrito é desejado.
Experimentos
Os experimentos desta seção foram realizados em hardware real utilizando a placa
LP-AM243
(AM243x General Purpose LaunchPad™ Development Kit), executando código no núcleo
Arm® Cortex®-R5F (R5FSS0-0) em modo NoRTOS. O desenvolvimento foi baseado no
MCU+ SDK for AM243x da Texas Instruments, utilizando como ponto de partida o exemplo
dpl_demo, que já fornece infraestrutura de inicialização e medição de tempo por meio do
contador de ciclos da CPU (CycleCounterP). Essa configuração permite avaliar, de forma
reprodutível, o impacto de diferentes padrões de acesso à memória no comportamento do cache.
Experimento 1: Localidade Espacial e Cache — Row-Major vs Column-Major
Neste primeiro experimento, avaliamos o impacto da ordem de acesso à memória em um arranjo bidimensional, comparando dois padrões clássicos: row-major e column-major. Em ambos os casos, o algoritmo executa exatamente o mesmo número de operações aritméticas e o mesmo número de acessos à memória, percorrendo todos os elementos da matriz uma única vez. A única diferença entre as versões está na ordem em que esses elementos são visitados. Quando a matriz é percorrida por linhas (row-major), o padrão de acesso coincide com o layout natural da linguagem C, no qual os elementos de uma mesma linha estão armazenados de forma contígua na memória. Esse padrão corresponde a um acesso com stride-1, explorando fortemente a localidade espacial e permitindo que cada linha de cache carregada seja amplamente reutilizada. Em contraste, ao percorrer a matriz por colunas (column-major), o código passa a acessar elementos separados por um grande deslocamento na memória, equivalente ao tamanho de uma linha inteira da matriz. Embora o número total de acessos permaneça o mesmo, esse padrão resulta em baixa localidade espacial, maior taxa de faltas de cache e, consequentemente, maior tempo de execução. Assim, o experimento evidencia que alterações aparentemente triviais na estrutura dos loops podem ter um impacto significativo no aproveitamento da hierarquia de memória.
Experimento de localidade espacial em cache no AM243x (row-major vs column-major)
#define MAT_ROWS 128 // Número de linhas da matriz
#define MAT_COLS 128 // Número de colunas da matriz
static uint32_t gMatrix[MAT_ROWS][MAT_COLS]
__attribute__((aligned(64))); // Matriz 128x128 (64 KB), alinhada a cache line
volatile uint32_t gResultSink; // Evita que o compilador elimine os loops
static uint32_t accumulate_by_rows(void); // Protótipo: acesso por linhas
static uint32_t accumulate_by_columns(void); // Protótipo: acesso por colunas
static uint32_t accumulate_by_rows(void) // Função com boa localidade espacial
{
uint32_t r, c; // Índices da matriz
uint32_t acc = 0; // Acumulador da soma
for (r = 0; r < MAT_ROWS; r++) // Percorre linhas (row-major)
{
for (c = 0; c < MAT_COLS; c++) // Percorre colunas sequencialmente
{
acc += gMatrix[r][c]; // Acesso contíguo na memória (boa localidade)
}
}
return acc; // Retorna soma total
}
static uint32_t accumulate_by_columns(void) // Função com localidade espacial ruim
{
uint32_t r, c; // Índices da matriz
uint32_t acc = 0; // Acumulador da soma
for (c = 0; c < MAT_COLS; c++) // Percorre colunas primeiro
{
for (r = 0; r < MAT_ROWS; r++) // Salta grandes distâncias na memória
{
acc += gMatrix[r][c]; // Quebra da localidade espacial
}
}
return acc; // Retorna soma total
}
void dpl_demo_main(void *args) // Função principal do exemplo DPL
{
uint32_t start, end, delta; // Variáveis de medição em ciclos
uint32_t r, c; // Índices auxiliares
uint32_t sum; // Resultado das somas
DebugP_log(0); // Sincronização inicial do console
for (r = 0; r < MAT_ROWS; r++) // Inicialização da matriz
{
for (c = 0; c < MAT_COLS; c++) // Preenchimento determinístico
{
gMatrix[r][c] = r + c; // Valor simples e reprodutível
}
}
CycleCounterP_reset(); // Zera o contador de ciclos
start = CycleCounterP_getCount32(); // Marca início (boa localidade)
sum = accumulate_by_rows(); // Executa acesso row-major
gResultSink = sum; // Impede otimização
end = CycleCounterP_getCount32(); // Marca fim
delta = end - start; // Calcula ciclos gastos
DebugP_log(delta); // Exibe tempo da boa localidade
CycleCounterP_reset(); // Zera contador novamente
start = CycleCounterP_getCount32(); // Marca início (localidade ruim)
sum = accumulate_by_columns(); // Executa acesso column-major
gResultSink = sum; // Impede otimização
end = CycleCounterP_getCount32(); // Marca fim
delta = end - start; // Calcula ciclos gastos
DebugP_log(delta); // Exibe tempo da localidade ruim
}
Resultado
A seguir são apresentados os resultados obtidos durante a execução do experimento no Code Composer Studio, mostrando os tempos medidos em ciclos de CPU para os dois padrões de acesso à memória avaliados. As medições foram coletadas diretamente no console de debug, utilizando o contador de ciclos do núcleo Arm® Cortex®-R5F, o que permite comparar de forma objetiva o impacto da localidade espacial no desempenho do cache.

Experimento 2 — Acesso à Memória com Cache Desabilitado
Neste segundo experimento, o cache de dados e de instruções do processador foi explicitamente
desabilitado antes da execução dos testes, por meio da chamada à função
CacheP_disable(CacheP_TYPE_ALL). Essa modificação foi inserida imediatamente antes
do bloco experimental, mantendo inalterados o tamanho da matriz, o número de acessos à memória
e o corpo dos loops utilizados no Experimento 1. O objetivo é isolar o impacto do cache no
desempenho observado anteriormente e verificar se a vantagem do acesso row-major
persiste quando todos os acessos passam a ser atendidos diretamente pela memória.
Resultado
Com o cache desabilitado, o tempo de execução aumentou significativamente em ambos os casos. Comparando com o Experimento 1 (cache habilitado), o acesso row-major passou de aproximadamente 460 mil ciclos para cerca de 5,45 milhões de ciclos, representando um aumento de cerca de 12 vezes. De forma semelhante, o acesso column-major apresentou tempo praticamente idêntico, também em torno de 5,45 milhões de ciclos. A diferença entre os dois padrões tornou-se estatisticamente irrelevante, evidenciando que, na ausência de cache, a ordem de acesso à matriz deixa de influenciar o desempenho. Esse resultado confirma que o ganho observado no Experimento 1 é consequência direta da exploração da localidade espacial pelo cache.

Os resultados do Experimento 2 demonstram que, sem a presença do cache, não há benefício mensurável associado à localidade espacial. Embora o custo total de acesso à memória aumente significativamente, a ordem de varredura da matriz deixa de ser um fator relevante para o desempenho. Em conjunto com o Experimento 1, esses resultados estabelecem de forma clara a relação causal entre localidade de memória, cache e tempo de execução no AM243x.
Experimento 3 — Impacto do Estado do Cache no Determinismo Temporal
Neste terceiro experimento, o objetivo é demonstrar que, mesmo com o cache habilitado, o tempo de execução do mesmo código pode variar em função do estado inicial do cache, caracterizando perda de determinismo temporal. Para isso, foi reutilizado exatamente o mesmo código do Experimento 1, incluindo o tamanho da matriz, o número de acessos à memória e a metodologia de medição em ciclos de CPU. A única diferença introduzida foi a execução de uma rotina de poluição de cache imediatamente antes do início do experimento, alterando propositalmente o conteúdo do cache sem modificar o código principal.
O experimento foi dividido em duas fases executadas sequencialmente no mesmo boot do sistema. Na primeira fase (baseline), o acesso à matriz foi realizado com o cache habilitado e sem qualquer interferência prévia, representando um estado inicial de cache relativamente limpo. Na segunda fase, uma rotina adicional foi executada antes do experimento com o objetivo de poluir o cache, acessando regiões de memória com baixa localidade espacial. Em ambas as fases, foram medidos os tempos de execução para os acessos row-major (por linhas) e column-major (por colunas).
Resultado
Os resultados mostraram que, embora o código executado fosse idêntico nas duas fases, os tempos medidos apresentaram variações mensuráveis. No caso do acesso row-major, o tempo passou de aproximadamente 485 mil ciclos na execução sem poluição para cerca de 491 mil ciclos após a poluição do cache, representando uma variação de aproximadamente 1%. Para o acesso column-major, observou-se uma variação de aproximadamente 0,4%, com redução no número de ciclos após a poluição.
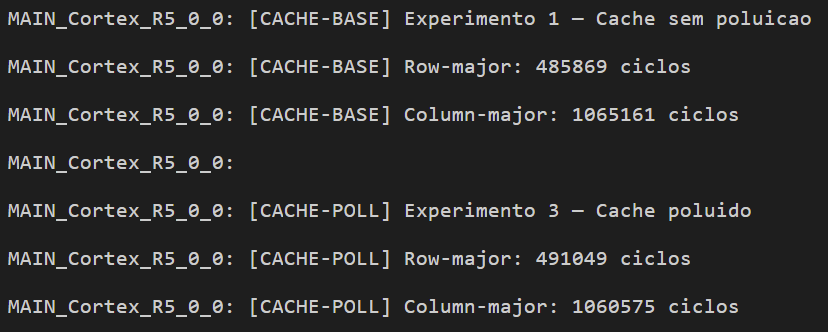
Embora as variações observadas sejam relativamente pequenas em termos absolutos, elas são tecnicamente significativas, pois ocorrem sem qualquer alteração no código, nos dados ou na plataforma de execução. A única variável modificada foi o estado interno do cache, que não é explicitamente controlado pelo programador. Esse resultado demonstra que, com o cache habilitado, o tempo de execução deixa de ser estritamente determinístico, passando a depender do histórico de acessos à memória e do conteúdo prévio do cache.
Conclusão Principal
Em conjunto, os três experimentos demonstram de forma clara o papel do cache no desempenho e no comportamento temporal do sistema. O primeiro experimento evidenciou que o cache melhora significativamente o desempenho ao explorar a localidade espacial, reduzindo o número de ciclos necessários para acessar a memória quando o padrão de acesso é favorável. O segundo experimento mostrou que a desativação do cache resulta em uma queda expressiva de eficiência, levando a tempos de execução muito superiores e praticamente independentes do padrão de acesso à matriz. Por fim, o terceiro experimento confirmou que, com o cache habilitado, o tempo de execução passa a depender do estado interno do sistema, uma vez que variações no estado inicial do cache são suficientes para produzir diferenças mensuráveis no número de ciclos executados. Esses resultados reforçam o trade-off fundamental entre desempenho e previsibilidade temporal, justificando o cuidado no uso do cache em sistemas críticos de tempo real, onde análises temporais rigorosas são essenciais.
Code Availability
O código-fonte do experimento, está disponível no GitHub:


Comentários e discussões